Veritabanı Kümesinin Mantıksal Yapısı
Database(DB) cluster, çalışan bir veritabanı sunucusunun tek bir instance’ı tarafından yönetilen veritabanı koleksiyonudur. PostgreSQL sunucusu tek bir hostta çalışır ve tek DB clusterını yönetir. Aynı host üzerinde farklı port numaralarında birden fazla PostgreSQL instance çalıştırmak mümkündür.
İlişkisel veritabanı teorisinde, datayı depolamak ya da referans vermek için kullanılan veri yapılarına Database Object (veritabanı nesnesi) denir. Tablo (heap), indeks, sequence, view ve function DB objelerinin en tipik örneğidir. Database ise tam olarak bu objelerin toplamına denir. Şöyle ki; PostgreSQL’de aslında DB’lerin kendiside de birer nesnedir ve mantıksal olarak biribirinden ayrılır. Verilen diğer tüm DB nesneleri ilişkili database aittir. Daha iyi anlamak için DB clusterının mantıksal yapısı:
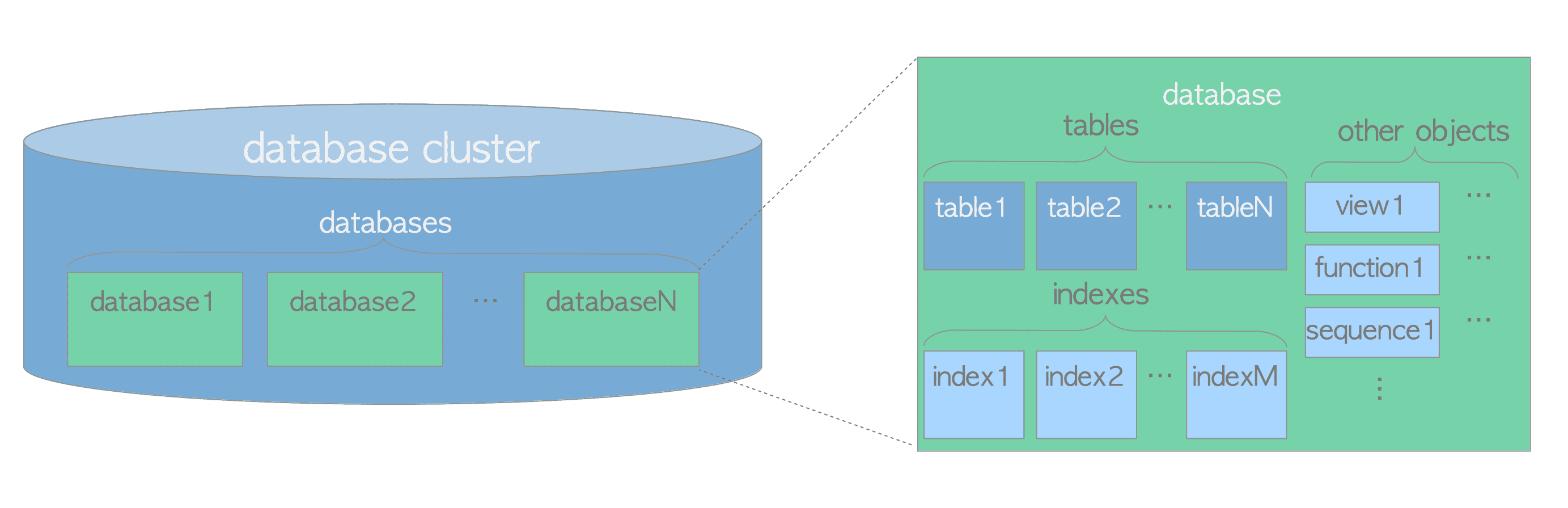
Postgres DB nesnelerini unique olarak ifade etmek için sistem tablolarında Object Identifiers (OIDs) kullanır. DB nesneleri ve ilgili OID’ler arasındaki ilişki, nesnelerin türüne göre uygun sistem kataloglarında depolanır. Örneğin DB OID’leri pg_database, tablo OID’leri pg_class içinde depolanır. Bu OID’ler aşağıdaki sorgularla öğrenilebilir:
sampledb=# SELECT datname, oid FROM pg_database WHERE datname = 'sampledb';
datname | oid
----------+-------
sampledb | 16384
(1 row)
sampledb=# SELECT relname, oid FROM pg_class WHERE relname = 'sampletbl';
relname | oid
-----------+-------
sampletbl | 18740
(1 row)
Veritabanı Kümesinin Fiziksel Yapısı
DB cluster base directory ismindeki alanda tutulur. Bu disk alanı pekçok alt dizin ve dosya içerir. Varsayılan $PGDATA çevre değişkenin değeridir. PGDATA çevre değişkeninin gösterdiği varsayılan dizin yerine istenirse yeni DB cluster başlatırken initdb yardımcı programıyla verilen dizin altında bir base directory oluşturulabilir. Her bir veritabanı, base directory altında base/ dizininde depolanır. Tablo ve indeksler ait olduğu veritabanı dizini altında depolanan (en az bir) birer dosyadır. base/ dizini ayrıca özel verileri ve yapılandırma dosyalarını içeren dizinleri tutar. DB cluster örneği:
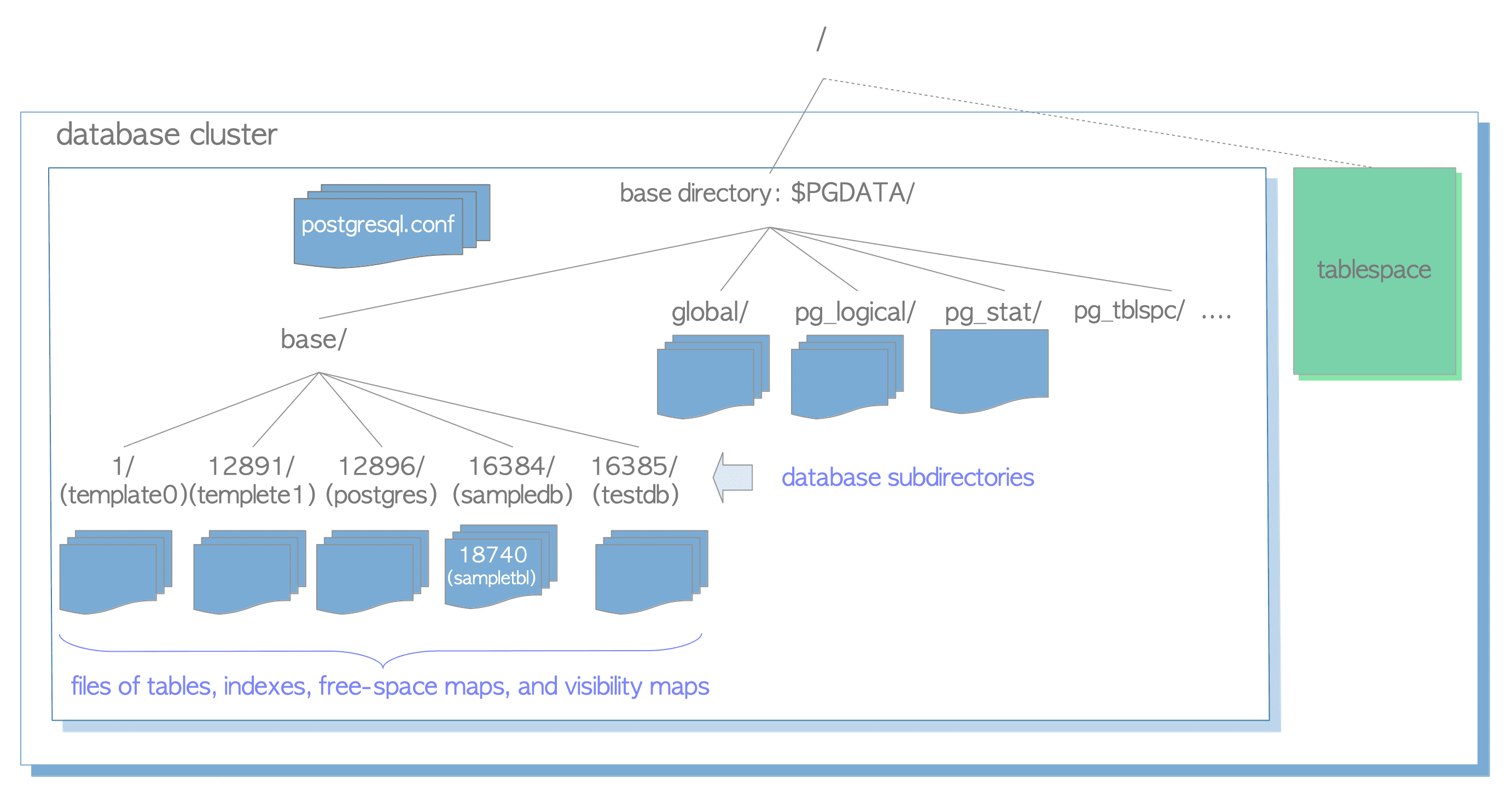
Veritabanı Kümesinin Düzeni
| Dosya | Tanım |
|---|---|
| PG_VERSION | PostgreSQL’in majör sürüm numarasını içeren dosya |
| pg_hba.conf | PosgreSQL istemci kimlik doğrulaması kontrolü dosyası |
| pg_ident.conf | PostgreSQL user name mapping kontrol dosyası |
| postgresql.conf | PostgreSQL yapılandırma parametrelerini ayarlama dosyası |
| postgresql.auto.conf | ALTER SYSTEM ile ayarlanan yapılandırma parametrelerini depolamak için kullanılan dosya |
| postmaster.opts | Sunucunun en son başlatıldığı komut satırı seçeneklerini kaydeden dosya |
| Alt Dizin | Tanım |
|---|---|
| base/ | Herbir veritabanının alt dizinlerini içeren alt dizin. |
| global/ | pg_database ve pg_control gibi cluster-wide tabloları içeren alt dizin. |
| pg_commit_ts/ | Transaction commit timestamp verilerini içeren alt dizin. |
| pg_clog/ (Version 9.6 ve öncesinde) | Transaction commit state verilerini içeren alt dizin. Sürüm 10’da pg_xact olarak yeniden adlandırılmıştır. |
| pg_dynshmem/ | Dynamic shared memory alt sistemi tarafından kullanılan dosyaları içeren alt dizin. |
| pg_logical/ | logical decoding için state verilerini içeren alt dizin. |
| pg_multixact/ | Shared row locks için kullanılan multitransaction status verilerini içeren alt dizin. |
| pg_notify/ | LISTEN / NOTIFY durum verilerini içeren alt dizin |
| pg_repslot/ | Replication slot verilerini içeren alt dizin. |
| pg_serial/ | Commit edilmiş serializable transaction’lar hakkında bilgi içeren alt dizin. |
| pg_snapshots/ | Dışa aktarılan anlık görüntüleri (snapshots) içeren alt dizin. PostgreSQL’in pg_export_snapshot işlevi bu alt dizinde bir snapshot bilgi dosyası oluşturur. |
| pg_stat/ | İstatistik alt sistemi için kalıcı dosyalar içeren alt dizin. |
| pg_stat_tmp/ | İstatistik alt sistemi için geçici dosyalar içeren alt dizin. |
| pg_subtrans/ | subtransaction status verilerini içeren alt dizin. |
| pg_tblspc/ | Tablespace’lerle sembolik bağlantıları içeren alt dizin. |
| pg_twophase/ | Prepared transaction’lar için durum dosyalarını içeren alt dizin. |
| pg_wal/ (Version 10 ve sonrasında) | WAL segment dosyalarını içeren alt dizin. Sürüm 10’da pg_xlog’dan yeniden adlandırılmıştır. |
| pg_xact/ (Version 10 ve sonrasında) | transaction commit state verilerini içeren alt dizin. Sürüm 10’da pg_clog’dan yeniden adlandırılmıştır. |
| pg_xlog/ (Version 10 ve öncesinde) | WAL segment dosyalarını içeren alt dizin. Sürüm 10’da pg_wal olarak yeniden adlandırılmıştır. |
Veritabanlarının Düzeni
Herbir veritabanı disk üzerinde base/ dizini altında bir alt dizin olarak tutulur. Bu dizinin ismi ilişkili OID ile aynıdır.
$ cd $PGDATA
$ ls -ld base/16384
drwx------ 213 postgres postgres 7242 8 26 16:33 16384
Tablo ve İndekslerin İlişkili Dosyalarla Düzeni
Her bir tablo ve index boyutu 1 GB’den küçük tek bir dosya halinde ait olduğu veritabanı dizini altında depolanır. Tablo ve indeks gibi database objeleri OID’ler üzerinden yönetilirken içerdiği data dosyaları relfilenode değişkeni aracılığıyla yönetilir. Tablo ve indexlerin relfilenode ve OID değeri temel olarak aynıdır, fakat bazı durumlarda değişir. Daha iyi anlamak için sampletbl’in OID ve relfilenode değerine bakalım:
sampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';
relname | oid | relfilenode
-----------+-------+-------------
sampletbl | 18740 | 18740
(1 row)
SELECT pg_relation_filepath('sampletbl') fonksiyonu da kullanılabilir.$ cd $PGDATA
$ ls -la base/16384/18740
-rw------- 1 postgres postgres 8192 Apr 21 10:21 base/16384/18740
Relfilenode değerleri TRUNCATE, REINDEX, CLUSTER komutları kullanıldığında değişir.
sampledb=# TRUNCATE sampletbl;
TRUNCATE TABLE
sampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';
relname | oid | relfilenode
-----------+-------+-------------
sampletbl | 18740 | 18812
(1 row)
Tablo ve indeks dosyalarının boyutu 1 GB’i aştığında PostgreSQL sırayla relfilenode[değeri].1, relfilenode[değeri].2 isminde yeni dosyalar oluşturur. Dosya boyutu 1 GB’yi aştığı her durumda bu şekilde devam eder. 1 GB dosya boyutu için varsayılan değerdir, konfigrasyon dosyasındaki --with-segsize seçeneğiyle PostgreSQL build edilirken değiştirilebilir.
Veritabanı alt dizinlerinde her tablonun sırasıyla _fsm (free space map) ve _vm (visibility map) ile sonlandırılmış iki ilişkili dosya vardır. Bunlar tablonun her bir page’indeki boş alan kapasitesi ve görünürlük bilgilerini depolar. _fsm tablo/indeks’in data dosyasının ilk fork’u,_vm ise tablo data dosyasının ikinci forkudur. Data dosyasının fork numarası 0’dır. İndeksler yalnızca ‘_fsm’ dosyalarına sahiptir, ‘_vm’ dosyaları bulunmaz.
Tablespace
Postgres 8.0 ile birlikte gelen tablespace özelliği, data directory dışında bir veri alanını ifade eder. Tablespace’in iç yapısını ve data directory ile olan ilişkisi şekil 3’te verilmiştir.
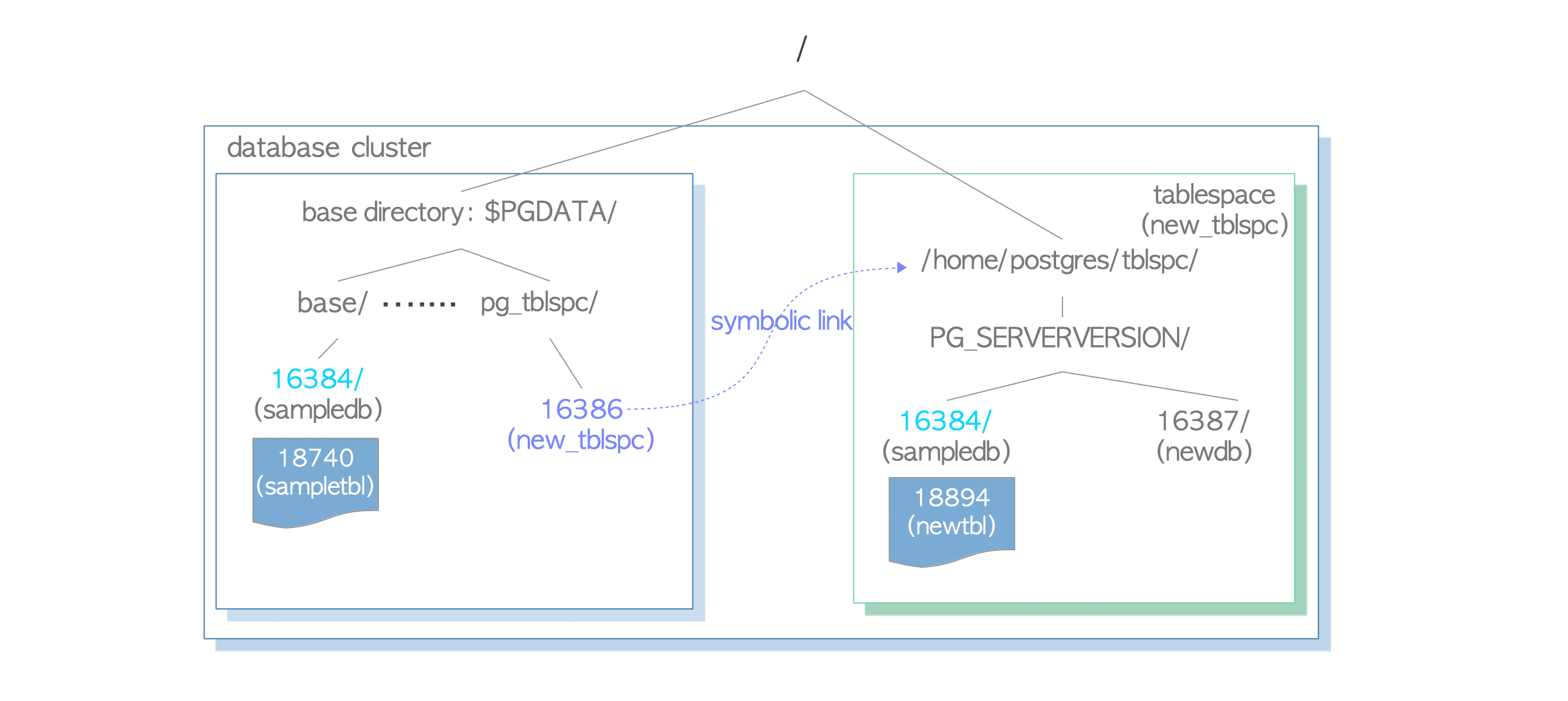
CREATE TABLESPACE komutu belirtilen dizin altında bir tablespace ve bu dizinin altında sürüme özgü PG_'Major version'_'Catalogue version number' formatında bir alt dizin oluşturur. (ör. PG_13_202009051). Tablespace kurulum ve kullanımı için Tablespace Kavramı ve Kullanımı sayfasına bakınız.
Heap Table Dosyasının İç Düzeni
Data dosyalarının (heap table, indeks, free space map, visibility map) içi default 8192 baytlık (8 KB) page(block)‘ler şeklinde bölünmüştür. Data dosyası içindeki page’ler 0’dan başlanarak sıralı şekilde numaralandırılır. Bu numaralara block numbers denilir. Eğer dosya doldurulmuşsa PostgreSQL, dosyanın sonuna yeni boş bir page ekler.
Page’lerin iç düzeni data dosyası türlerine göre değişir. Tablo için düzen şekil 4’te verilmiştir.
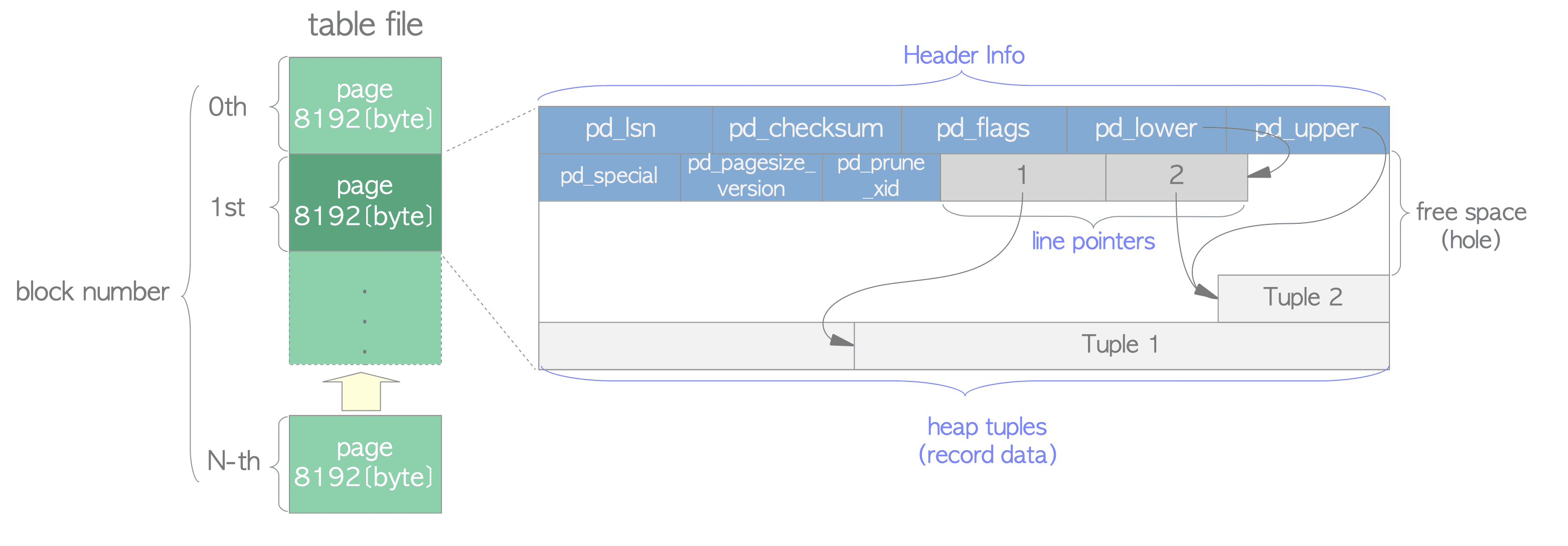
Tabloların data dosyası içindeki her bir page; heap tuple(s), line pointer(s) ve header data olmak üzere üç tür veri içerir:
heap tuple(s): Sayfanın altından başlanıp sıralı şekilde dizilen, asıl verinin kaydedildiği kısımdır.line pointer(s): Her bir heap tuple 4 baytlık line pointer (item pointer)’lar tarafından işaret edilir. Line pointerlar, Offset number denilen sıralı numaralar ile tuple’ların indekslendiği basit bir array formundadır. Page’e her tuple eklendiğinde yeni bir line pointer’da bu tuple’ı işaret etmesi için arraye eklenir.header data:Kaynak kodtaki PageHeaderData struct’ı tarafından tanımlanan header data, page’in en başında tutulur. 24 bayt uzunluğundaki header data, page hakkında genel bilgileri içerir. Struct’ın ana değişkenleri şunlardır:pd_lsn: 8-byte unsigned integer tipindeki bu değişken, page’de yapılan son değişikliğin XLOG kaydının LSN’ini saklarpd_checksum: Bu değişken, page’in checksum değerini tutar. (9.3 ve daha sonraki sürümlerde desteklenir.)pd_lower, pd_upper: pd_lower, line pointer’ın sonunu; pd_upper en yeni heap tuple’ın başını işaret eder.pd_special: İndeksler için olan bu değişken; tablolar içindeki page’lerin sonunu işaret ederken, indexler içindeki page’lerin ise B-Tree, GiST, GiN, vb. indeks türlerine göre belirli verileri içeren özel alanın başlangıcını işaret eder.
Line pointer’ın bitişi ve en yeni tuple’ın başlangıcı arasındaki boşluğa free space(hole) denir.
Tablo içinde bir tuple’ı belirtmek için tuple identifier (TID) kullanılır. TID, ilgili page’i içeren block number ve line pointer‘ı işaret eden offset number‘dan oluşur. İndeksler en tipik kullanım alanıdır.
Tuple Yazma ve Okuma Yöntemleri
Heap Tuple Yazma
Elimizde yalnızca bir heap tuple içeren ve bir page’den oluşan bir tablo olduğunu varsayalım. Burada page’in pd_lower değeri ilk line pointer’ı ve bu line pointer ile pd_upper değeride ise heap tuple’ı gösterir. Şekil 5 (a).
İkinci tuple geldiğinde, birinciden sonraki kısma yerleşir ve ikinci line pointer gelen tuple’ı işaret eder. pd_lower ikinci line pointer’ı ve pd_upper ikinci heap tuple’ı gösterecek şekilde değişir. Şekil 5 (b). Page’deki header verileri de (pd_lsn, pg_checksum, pg_flag) uygun değerlerle değiştirilir.
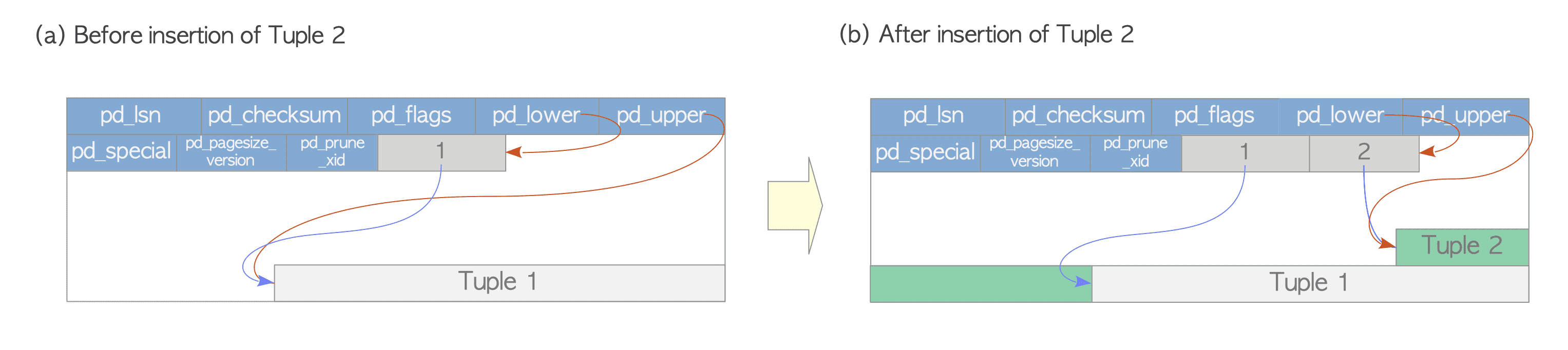
Heap Tuple Okuma
En tipik erişim metodu olan sequential scan ve B-tree index scan’i özetleyecek olursak:
Sequential scan: Herbir page’deki tuple’lar, line pointer aracılığı ile sırayla taranarak okunur. Şekil 6(a).B-tree index scan: İndeks dosyaları; index key ve hedef heap tuple’ı işaret eden TID’den oluşanindex tuple‘larından oluşur. Aranan key’i tutan index tuple bulunursa, postgres elde edilen TID değerini kullanarak istenen heap tuple’ı okur. Örneğin Şekil 6(b)’de, bulunan index tuple’ın TID değeriblock=7,Offset=2dir. Bunun anlamı aranan heap tuple’ın tablonun 7. sayfasındaki 2. tuple olduğudur. PostgreSQL bu şekilde sayfalarda gereksiz tarama yapmadan istenen heap tuple’ı okur.
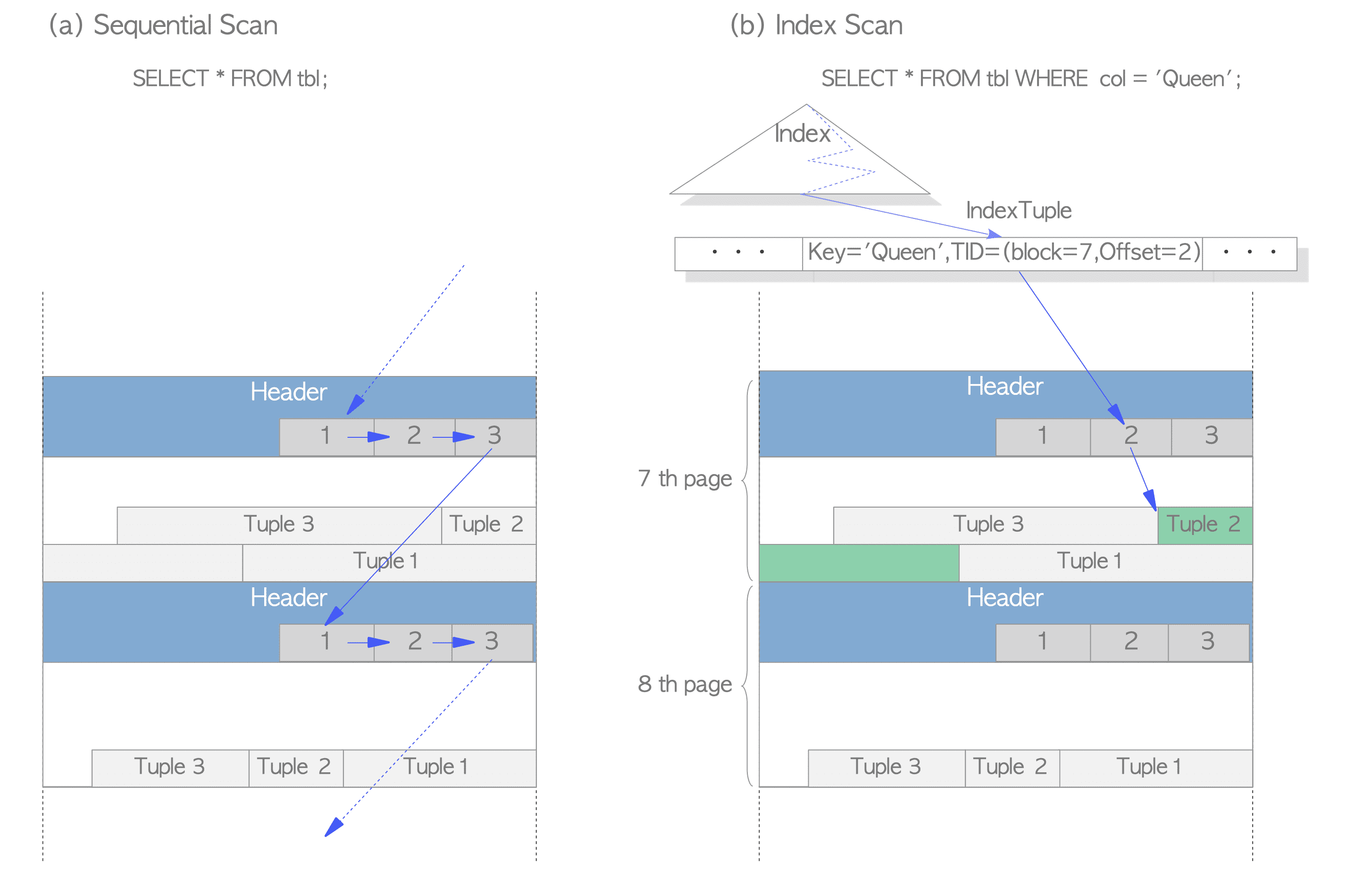
Kaynak:
[1]. The Internals of PostgreSQL